
Education
-
Ph.D. in Computer Science and Engineering, SungKyunKwan University
Sep. 2022 - Present
Specialist Research Personnel (전문연구요원), Sep. 2024 - Present
- M.S. in Computer Science and Engineering, SungKyunKwan University Mar. 2021 - Aug. 2022
- B.S. in Computer Science and Engineering, SungKyunKwan University Mar. 2017 - Feb. 2021
- High School, Korean Minjok Leadership Academy (민족사관고등학교) Mar. 2014 - Feb. 2017
Conference Publications
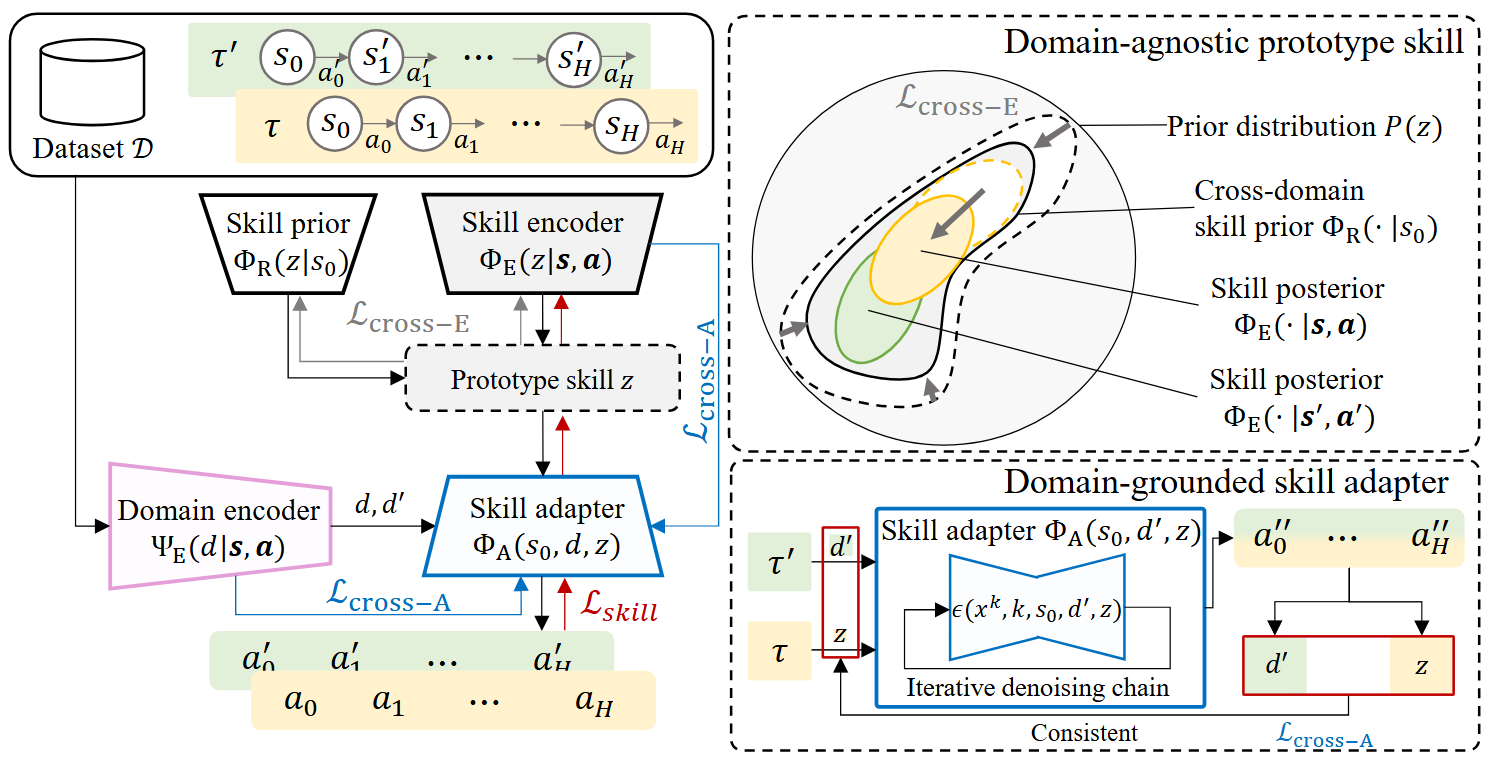
In this work, we present an in-context policy adaptation (ICPAD) framework designed for long-horizon multi-task environments, exploring diffusion-based skill learning techniques in cross-domain settings.
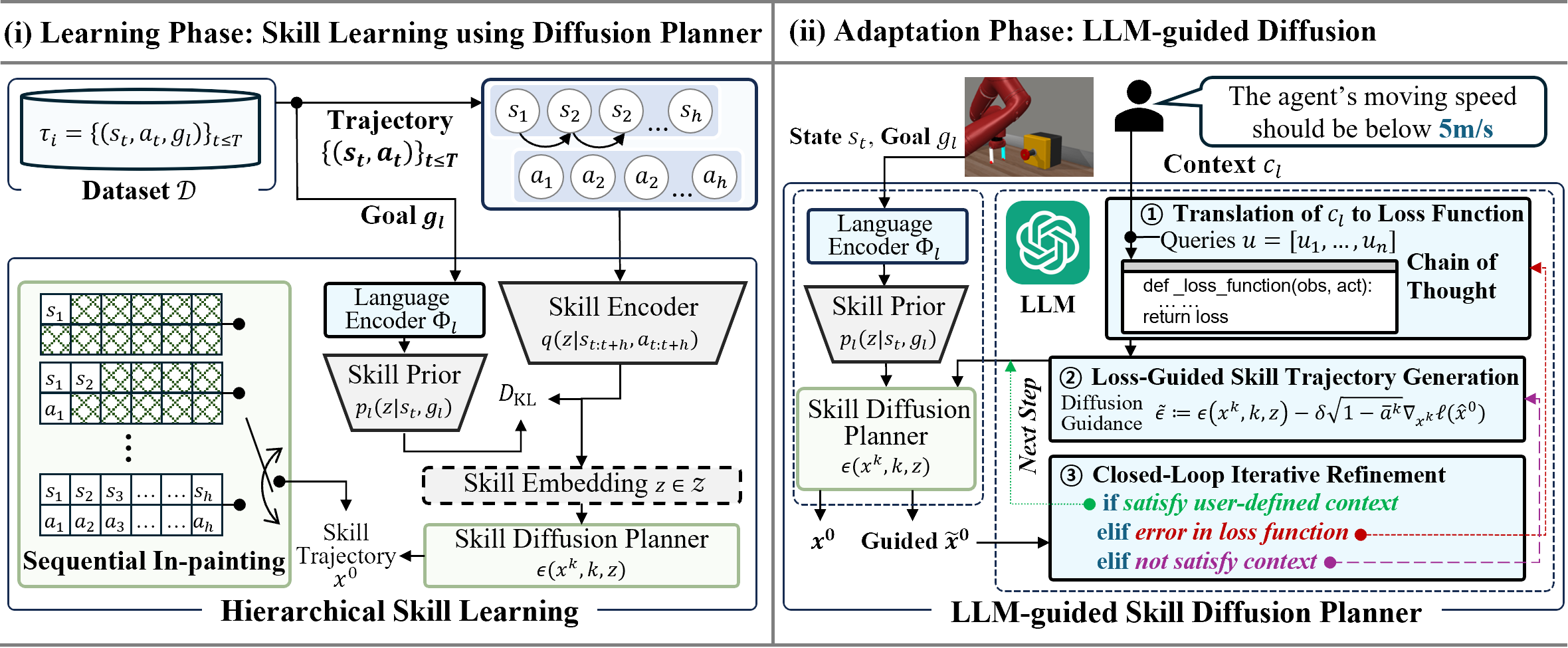
In this paper, we present a novel LLM-based policy adaptation framework LDuS which leverages an LLM to guide the generation process of a skill diffusion model upon contexts specified in language, facilitating zero-shot skill-based policy adaptation to different contexts.
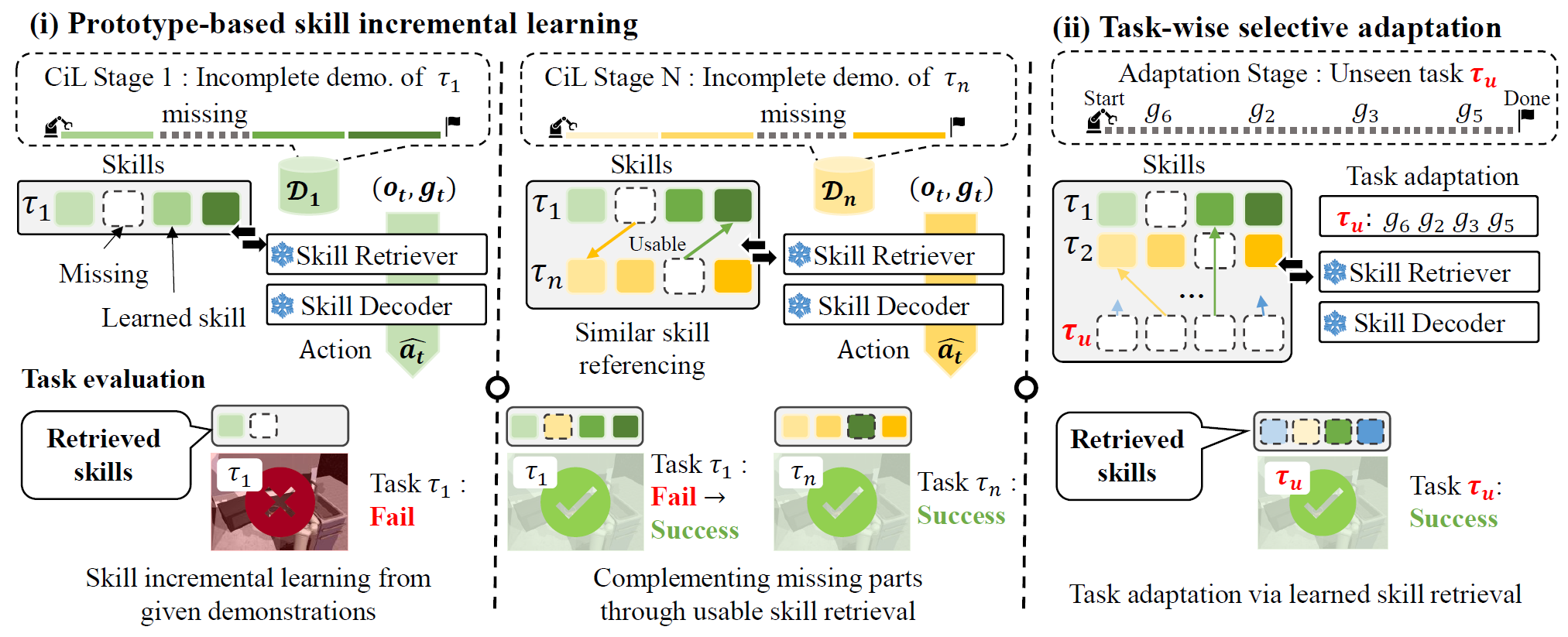
We introduce IsCiL, an adapter-based continual imitation learning framework that incrementally learns sharable skills from different demonstrations, enabling sample efficient task adaptation using the skills.
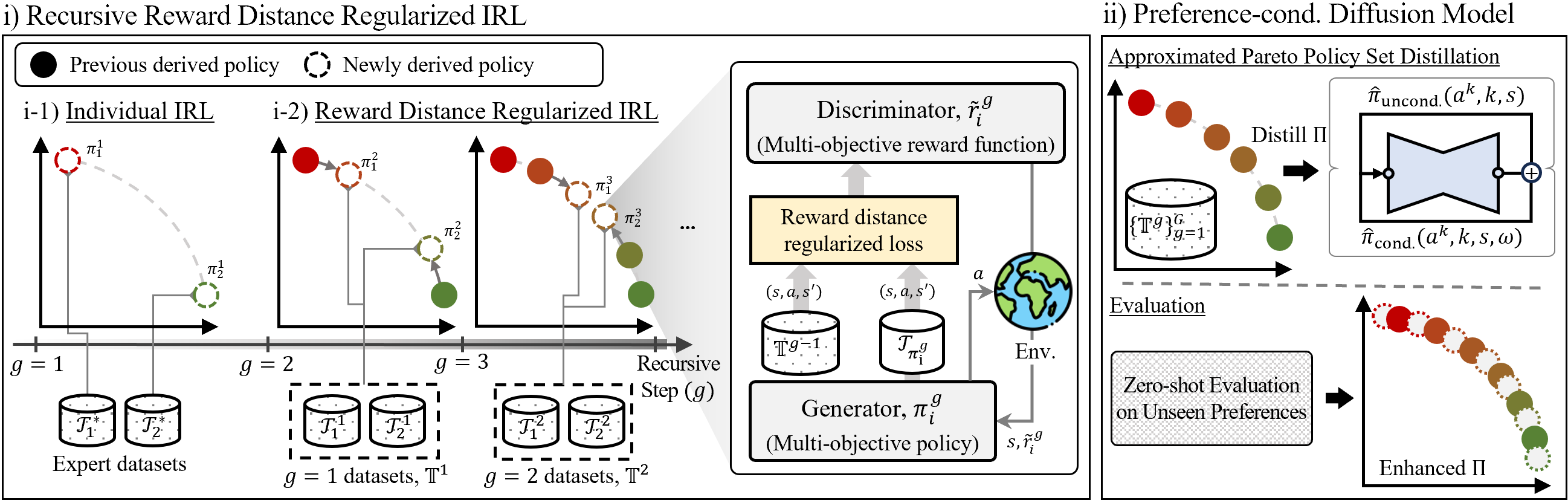
In this paper, we present Pareto inverse reinforcement learning (ParIRL) framework in which a Pareto policy set corresponding to the best compromise solutions over multi-objectives can be induced.
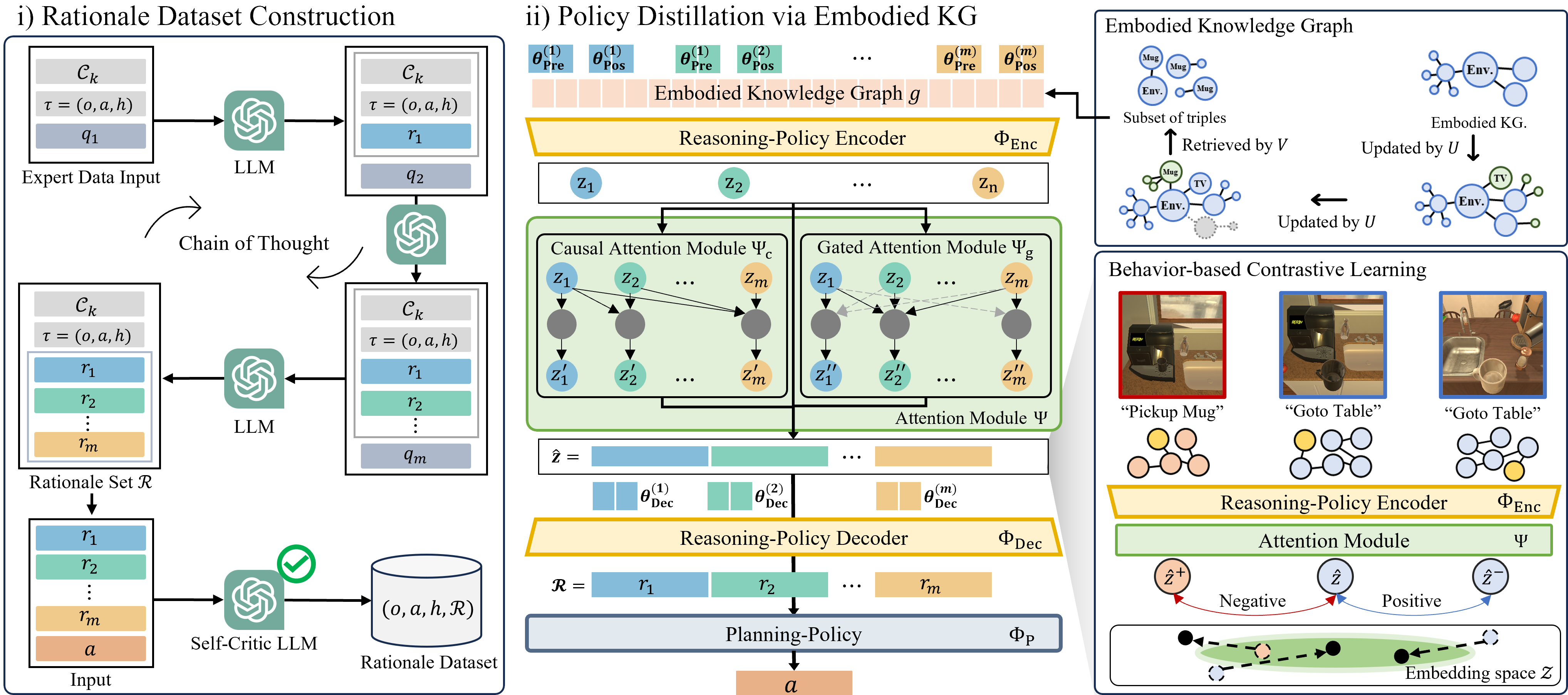
We present DEDER, a framework for decomposing and distilling the embodied reasoning capabilities from large language models (LLMs) to efficient, small language model (sLM)-based policies.
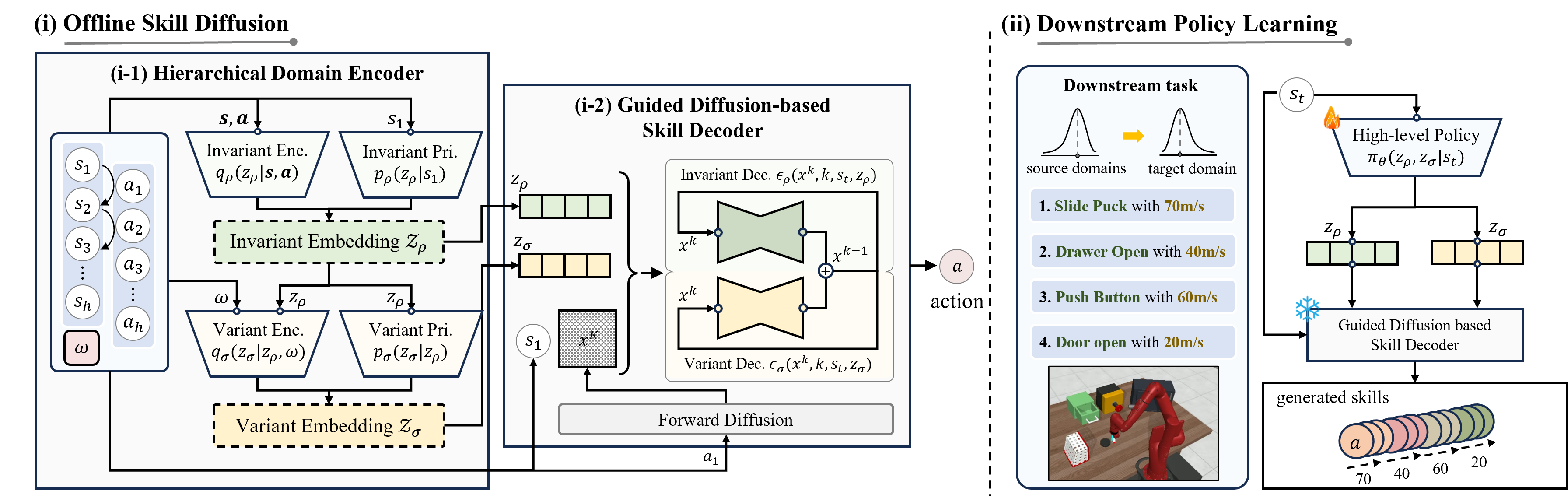
We present a novel offline skill learning (DuSkill) framework which employs a guided Diffusion model to generate versatile skills extended from the limited skills in datasets, thereby enhancing the robustness of policy learning for tasks in different domains.
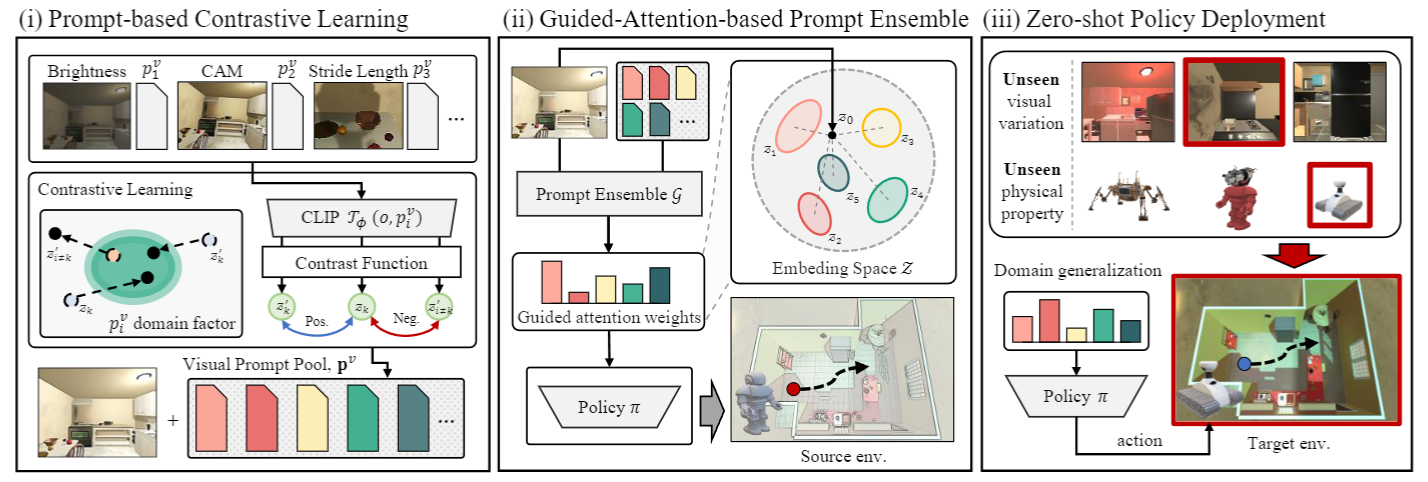
We present a novel contrastive prompt ensemble (ConPE) framework which utilizes a pretrained vision-language model and a set of visual prompts, thus enables efficient policy learning and adaptation upon environmental and physical changes encountered by embodied agents.
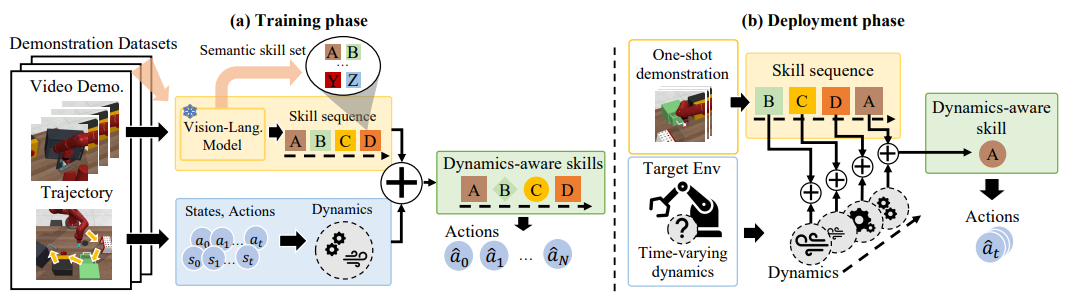
In this paper, we explore the compositionality of complex tasks, and present a novel skill-based imitation learning (OnIS) framework enabling one-shot imitation and zero-shot adaptation.
Journal Publications
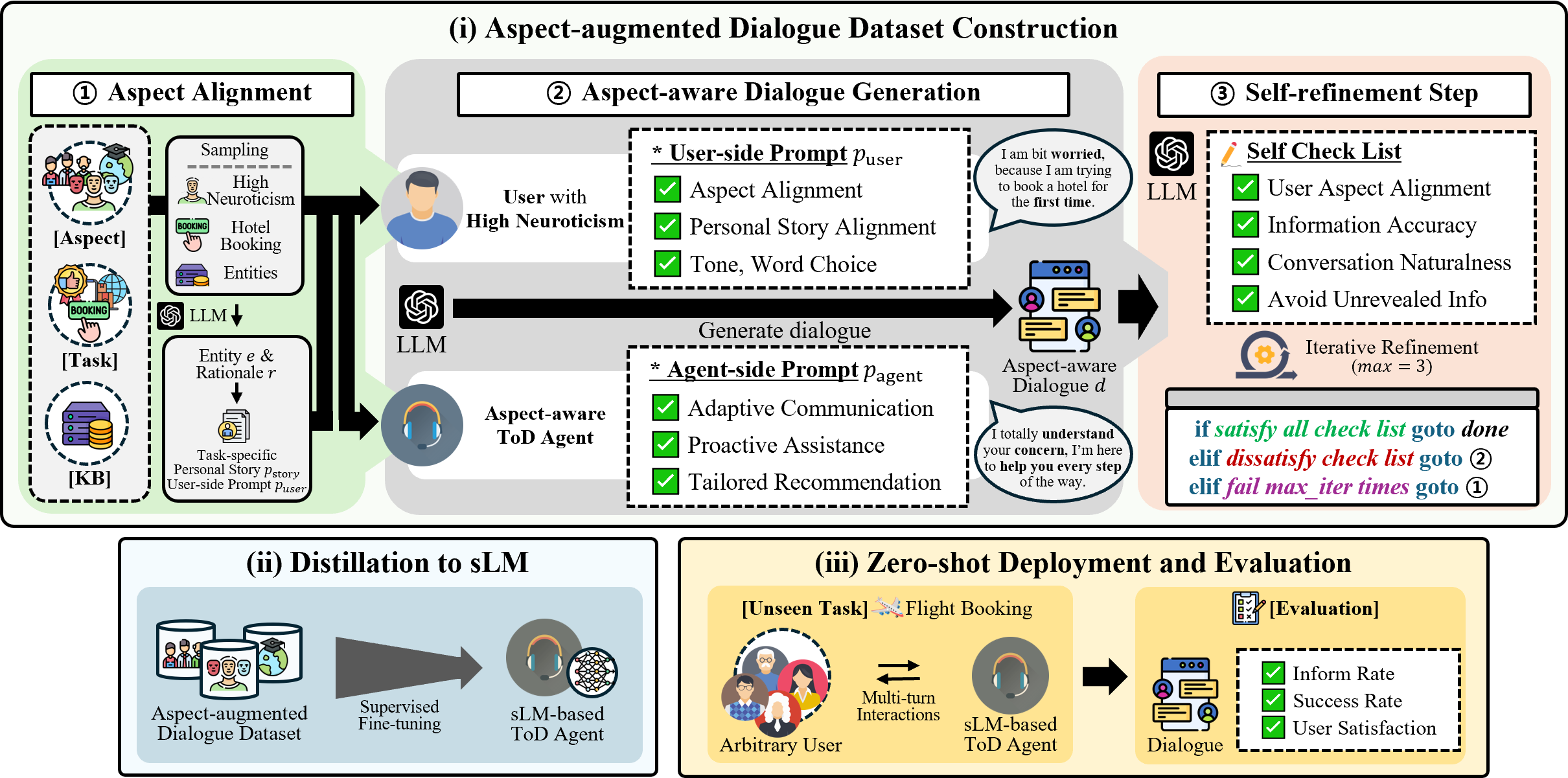
We present A2D2, an aspect-augmented dialogue distillation framework designed to transfer capabilities from larger language models to smaller ones for task-oriented dialogue systems, incorporating human aspect-aware capabilities while maintaining task requirements.
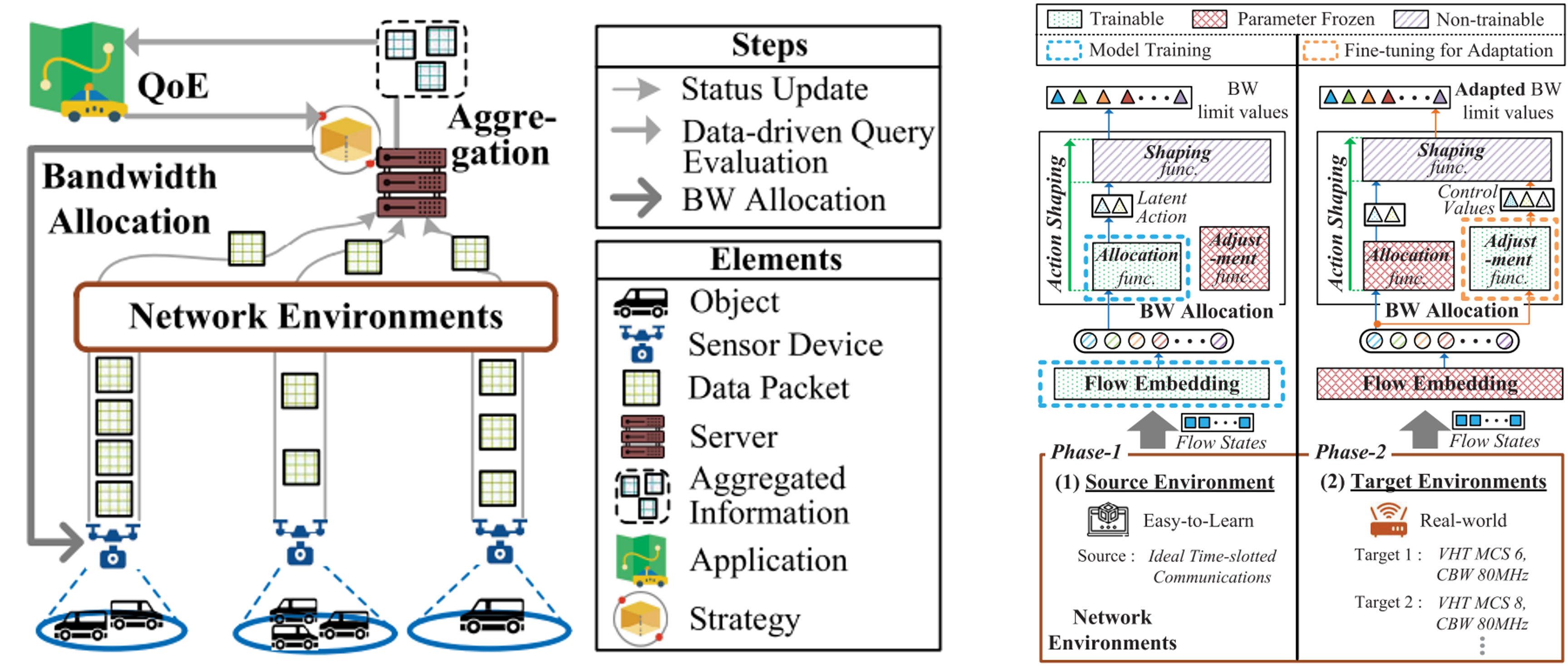
In this paper, we present a transferable RL model Repot in which a policy trained in an easy-to-learn network environment can be readily adjusted in various target network environments.