|
I am currently a PhD student at Computer Systems Intelligence (CSI) Lab in SungKyunKwan University, advised by Honguk Woo. My research areas include skill-based reinforcement learning, diffusion model, embodied agent. Google Scholar / CV / Github |

|
Conference Publications
|
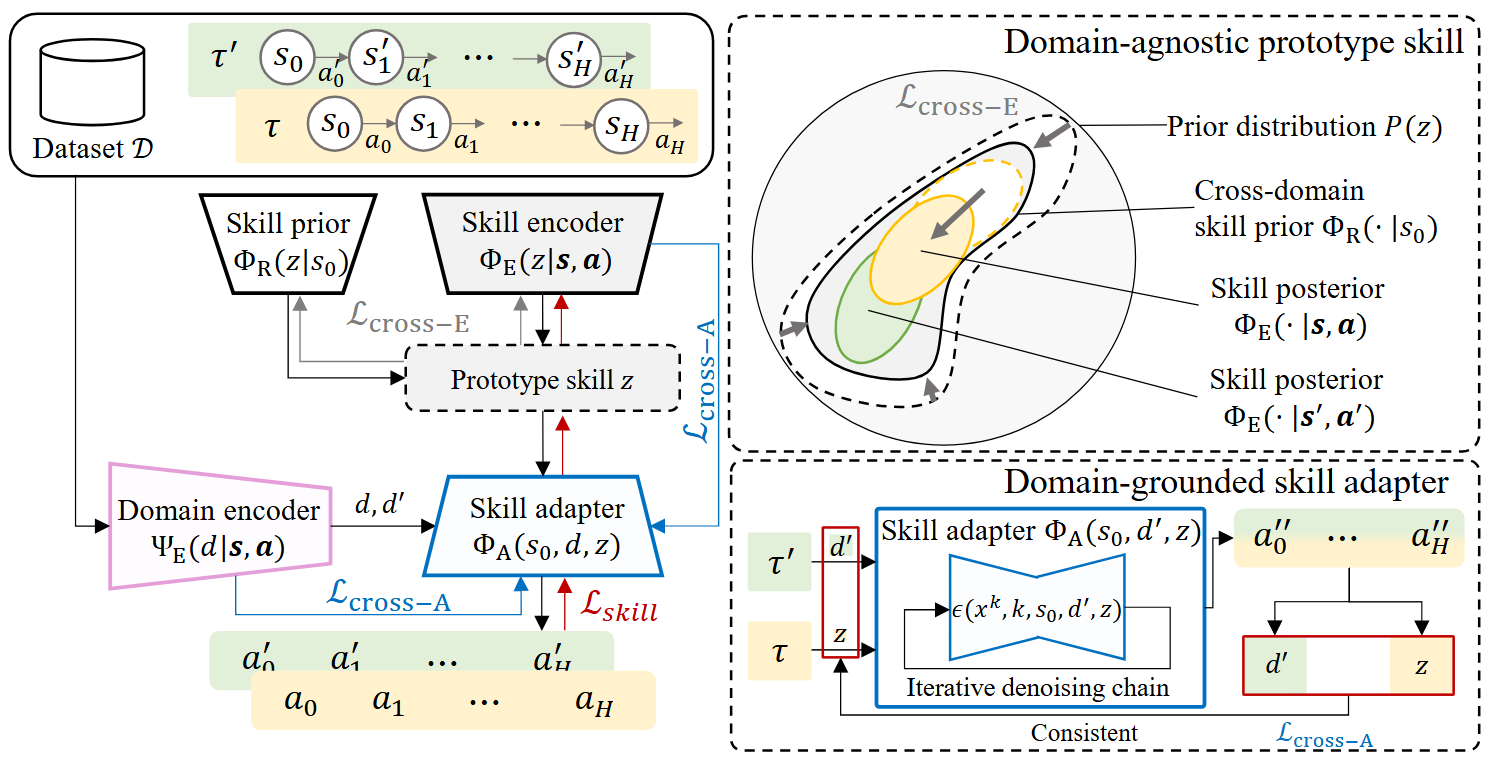
In-Context Policy Adaptation via Cross-Domain Skill Diffusion
Minjong Yoo*, Woo Kyung Kim, Honguk Woo AAAI, 2025.02, Philadephia, United States In this work, we present an in-context policy adaptation (ICPAD) framework designed for long-horizon multi-task environments, exploring diffusion-based skill learning techniques in cross-domain settings. |
|
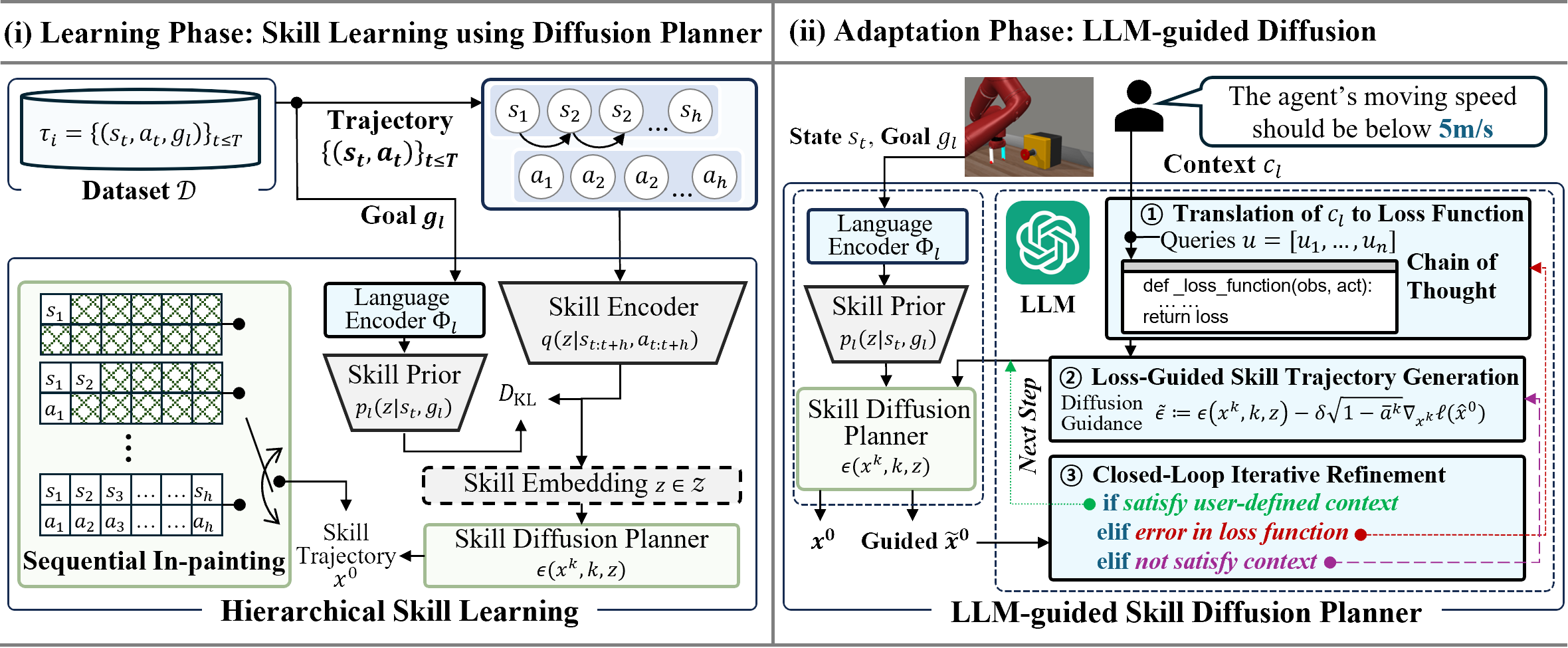
LLM-based Skill Diffusion for Zero-shot Policy Adaptation
Woo Kyung Kim*, Youngseok Lee, Jooyoung Kim, Honguk Woo NeurIPS, 2024.12, Vancouver, Canada In this paper, we present a novel LLM-based policy adaptation framework LDuS which leverages an LLM to guide the generation process of a skill diffusion model upon contexts specified in language, facilitating zero-shot skill-based policy adaptation to different contexts. |
|
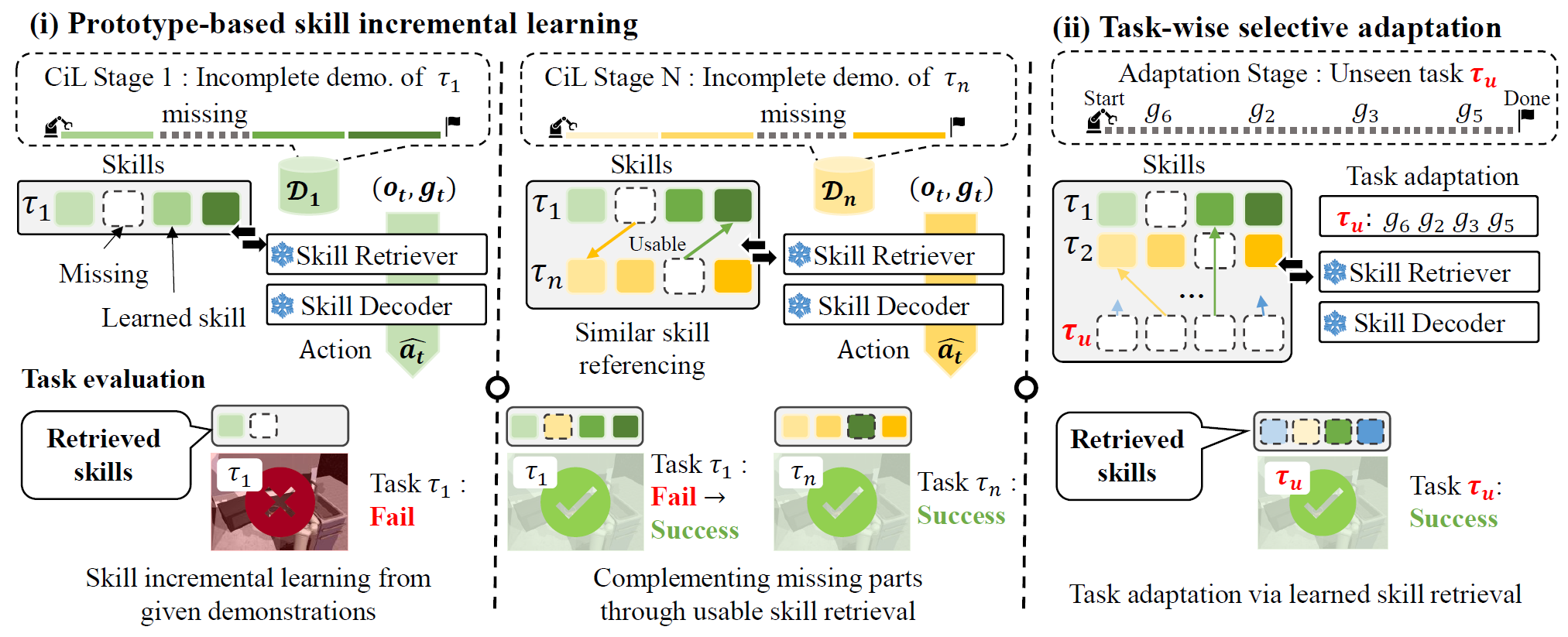
Incremental Learning of Retrievable Skills for Efficient Continual Task Adaptation
Daehee Lee*, Minjong Yoo, Woo Kyung Kim, Wonje Choi, Honguk Woo NeurIPS, 2024.12, Vancouver, Canada We intrudocue IsCiL, an adapter-based continual imitation learning framework that incrementally learns sharable skills from different demonstrations, enabling sample efficient task adaptation using the skills. |
|
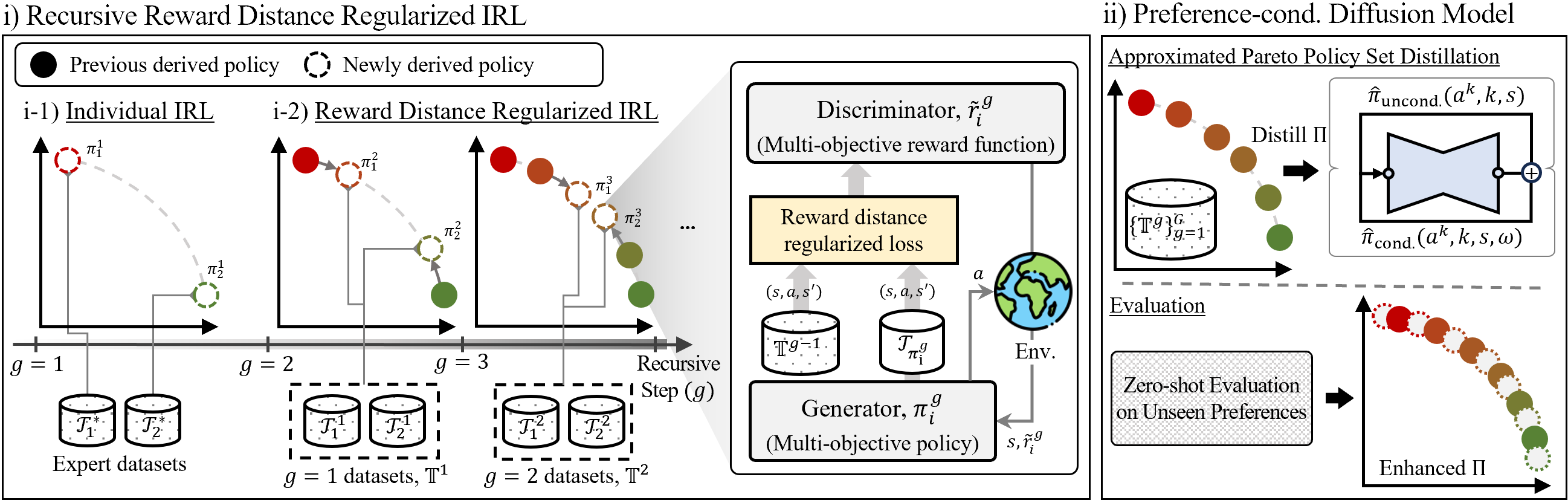
Pareto Inverse Reinforcement Learning for Diverse Expert Policy Generation
Woo Kyung Kim*, Minjong Yoo, Honguk Woo IJCAI, 2024.08, Jeju, Korea In this paper, we present Pareto inverse reinforcement learning (ParIRL) framework in which a Pareto policy set corresponding to the best compromise solutions over multi-objectives can be induced. |
|
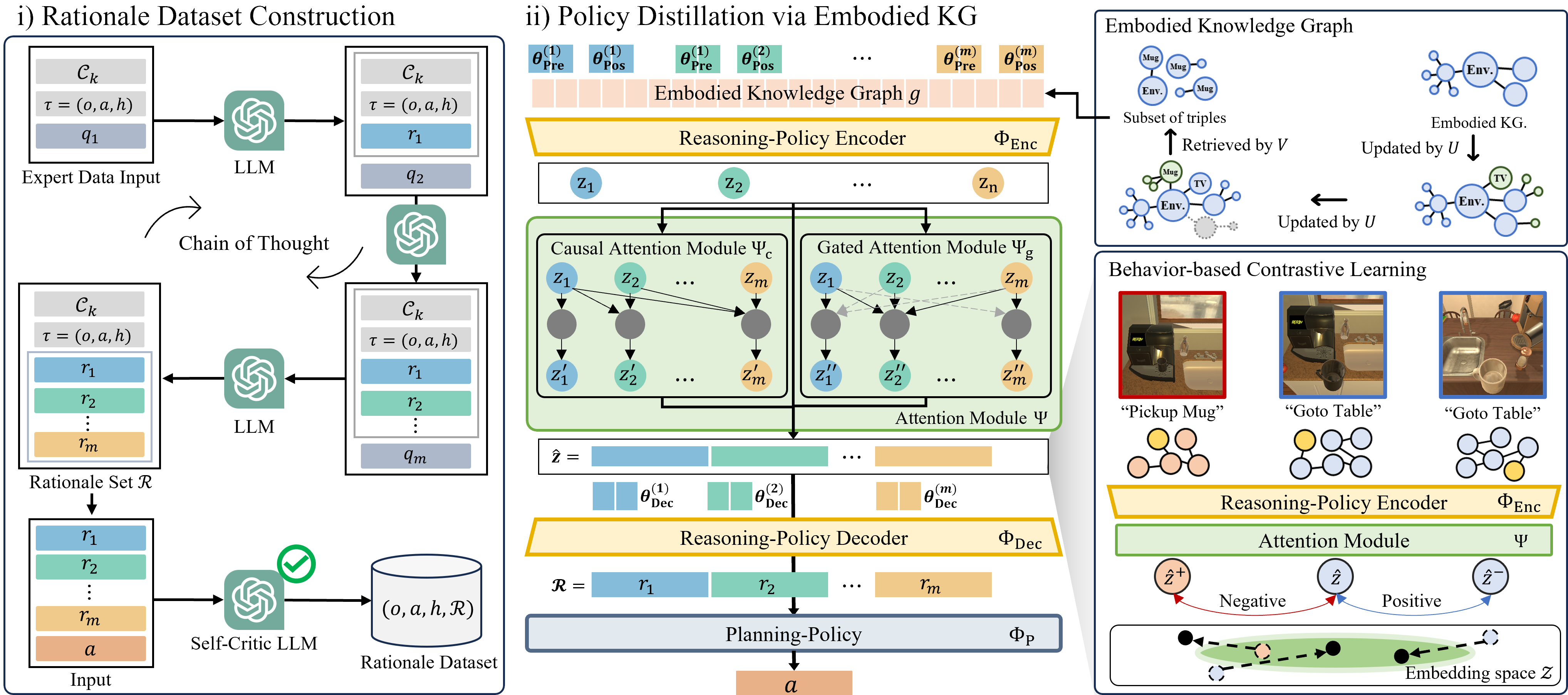
Embodied CoT Distillation From LLM To Off-the-shelf Agents
Wonje Choi*, Woo Kyung Kim, Minjong Yoo, Honguk Woo ICML, 2024.07, Wien, Austria We present DEDER, a framework for decomposing and distilling the embodied reasoning capabilities from large language models (LLMs) to efficient, small language model (sLM)-based policies. |
|
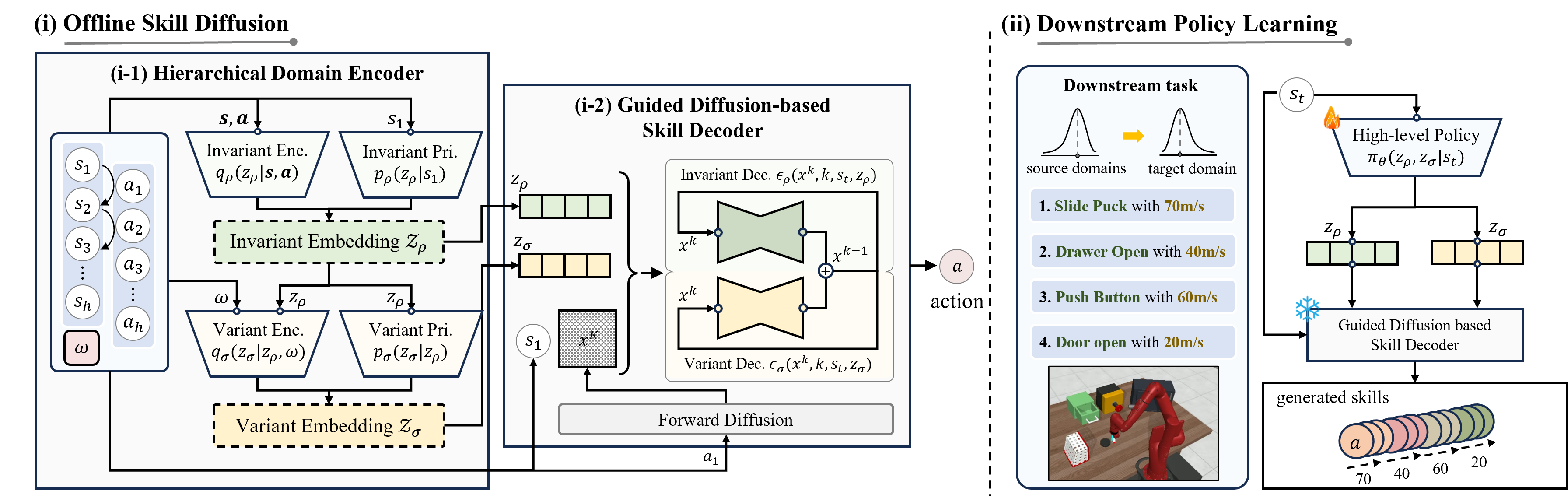
Robust Policy Learning via Offline Skill Diffusion
Woo Kyung Kim*, Minjong Yoo, Honguk Woo AAAI, 2024.02, Vancouver, Canada We present a novel offline skill learning (DuSkill) framework which employs a guided Diffusion model to generate versatile skills extended from the limited skills in datasets, thereby enhancing the robustness of policy learning for tasks in different domains. |
|
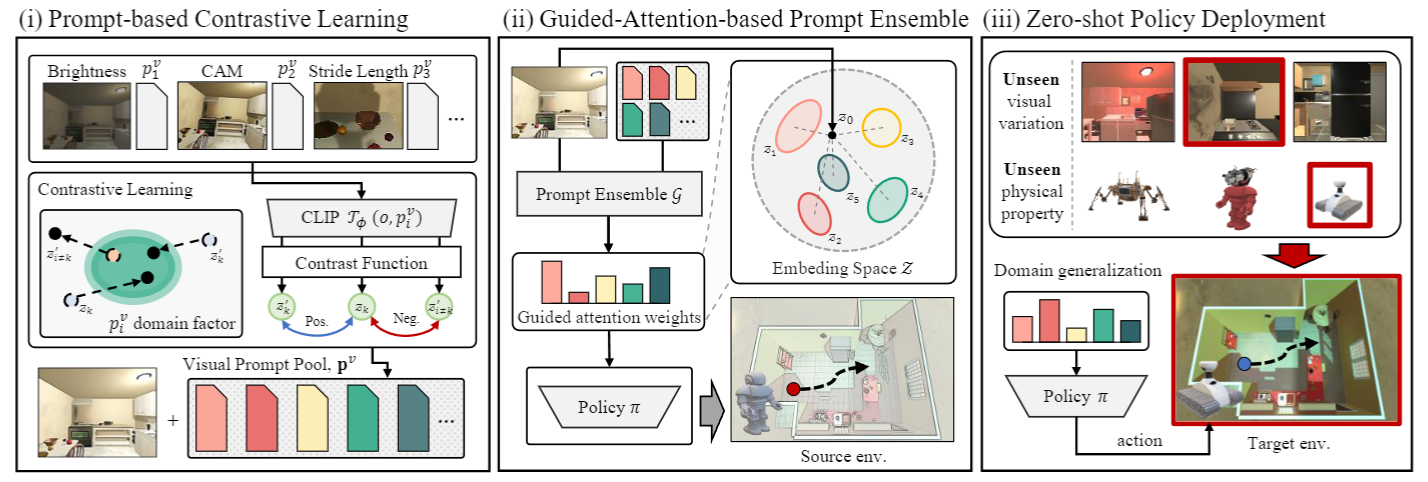
Efficient Policy Adaptation with Contrastive Prompt Ensemble for Embodied Agents
Wonje Choi*, Woo Kyung Kim, SeungHyun Kim, Honguk Woo NeurIPS, 2023.12, New Orleans, United States Wwe present a novel contrastive prompt ensemble (ConPE) framework which utilizes a pretrained vision-language model and a set of visual prompts, thus enables efficient policy learning and adaptation upon environmental and physical changes encountered by embodied agents. |
|
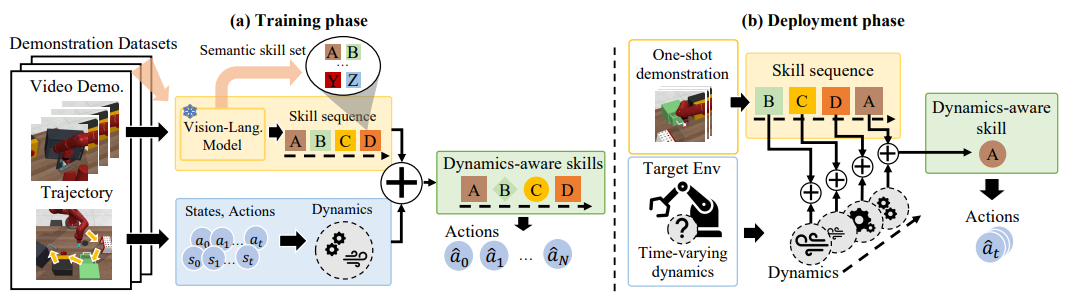
One-shot Imitation in a Non-stationary Environment via Multi-modal Skill
Sangwoo Shin*, Daehee Lee, Minjong Yoo, Woo Kyung Kim, Honguk Woo ICML, 2023.07, Honolulu, United States In this paper, we explore the compositionality of complex tasks, and present a novel skill-based imitation learning (OnIS) framework enabling one-shot imitation and zero-shot adaptation. |
Journal Publications
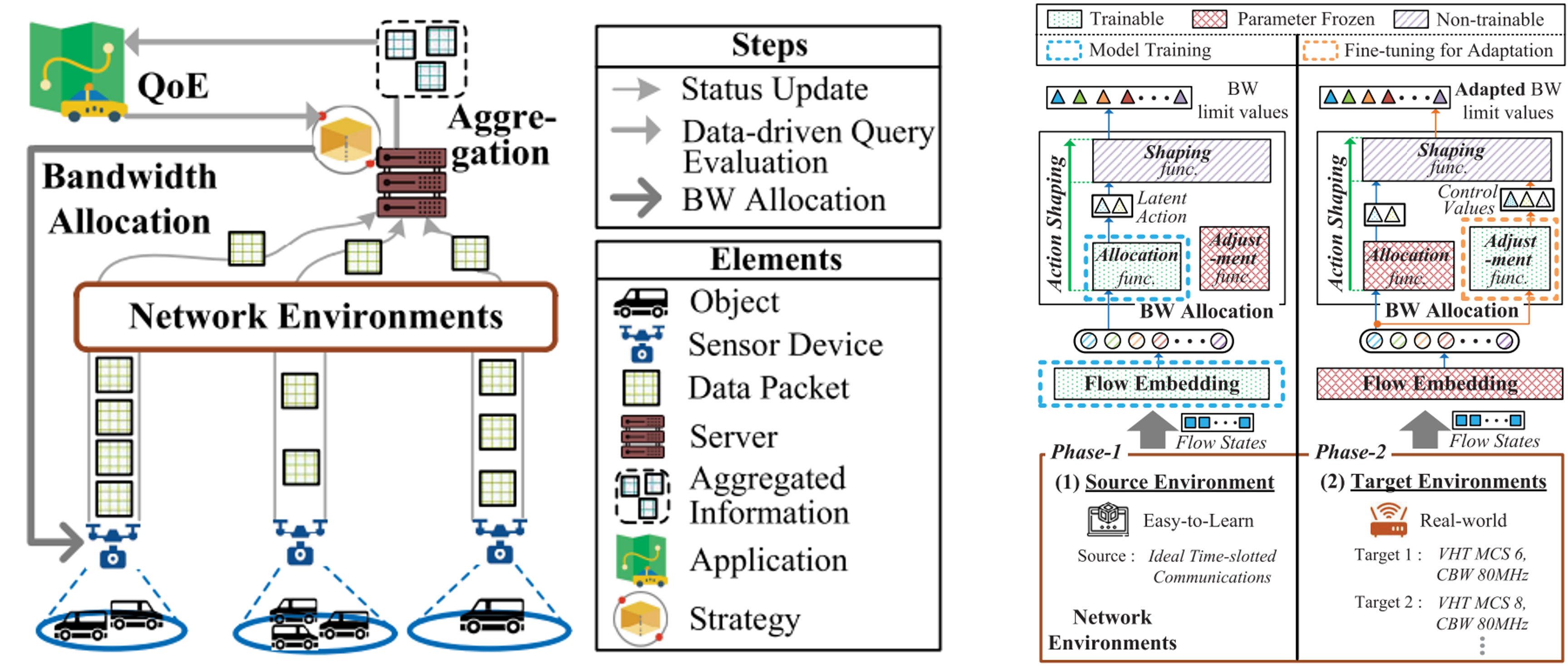
|
Repot: Transferable Reinforcement Learning for Quality-Centric Networked Monitoring in Various Environments
Youngseok Lee*, Woo Kyung Kim, Sung Hyun Choi, Honguk Woo IEE Access, 2023.11. Volume 9, Page 147280-147294 In this paper, we present a transferable RL model Repot in which a policy trained in an easy-to-learn network environment can be readily adjusted in various target network environments. |